Command Line MSSQL
There’s a number of tools out there for connecting to an MSSQL Database and running queries from the command line, but a colleague recently pointed out a new one I hadn’t seen before that actually works really really well, especially with Windows Terminal and Cmder.
First, make sure you’ve got Windows Terminal and Cmder installed. They are truly the bees knees when it comes to working in the command line under Windows!
Next, install mssql-cli. This app is actually a python script, so you’ll also need Python if you don’t already have it installed. Don’t fret, though. The link contains instructions on getting Python going, and once that’s done, installing mssql-cli is a single pip command:
python -m pip install mssql-cli
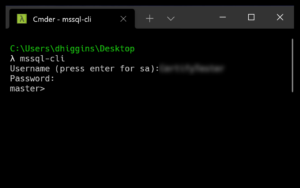
To test it, just open a command prompt and type:
mssql-cli
Now, that alone is nice, but if you’re like me, you have several test databases you connect to on a regular basis and entering credentials is troublesome at best.
Not to worry. There’s a batch file for that!
Now, it’s not the simplest in the world even though it is a single liner. So here goes:
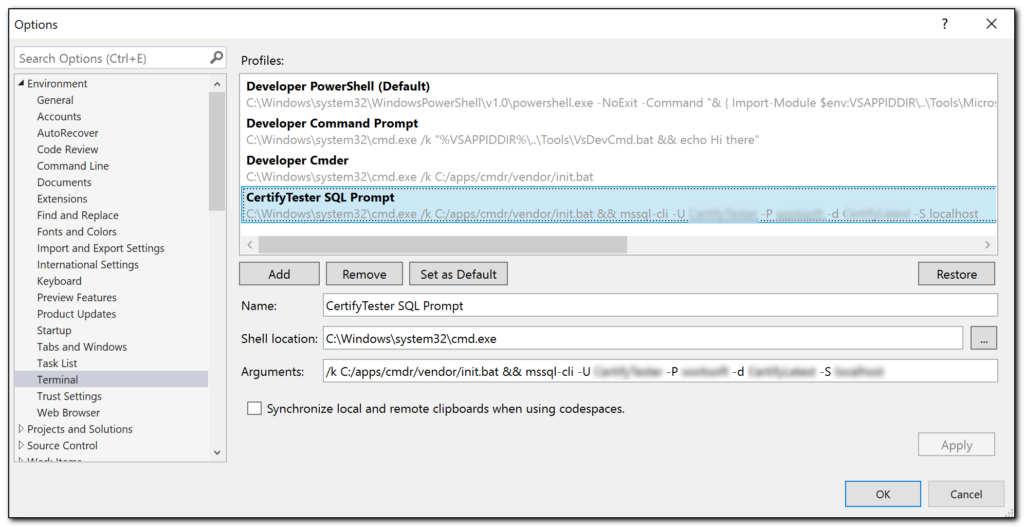
wt -d c:\users\dhiggins\desktop cmd /k "c:\apps\cmdr\vendor\init.bat cd %CD% && mssql-cli -U {dbloginusername} -P {password} -d {dbname} -S {dbservername}"
Let’s break that down:
- wt – starts Windows Terminal
- -d – followed by the folder you’d like to start terminal in. Not strictly required, but it’s a nice add. I just set it to my desktop
- cmd – This is used to get Cmder started in a tab in Windows Terminal
- /k – tells cmd to execute the following quoted command and stay loaded
- “c:/apps/cmdr/vendor/init.bat – this get Cmder started and the shell all initialized. Note that the path to your installed copy of Cmdr may be different from the “apps/cmdr” that I have here.
- cd %CD% – Gets Cmder switched to the folder that this bat file is located in
- && mssql-cli – Actually starts mssql-cli! The whole point of this exercise.
- -U {dbloginusername} – Provider the UserName you use to log into your db server here
- -P {password} – provide the database user password here
- -d {dbname} – provide the database name here
- -S {dbservername}” – And finally provide the database server name here. I’m just connecting up to the locally installed instance of SQL Server.
Save that as a BAT file and dblclick it to launch directly into a Cmder tab inside Windows Terminal connected to the DB of your choice. Perfection!
One big benefit from using Cmder, at least from what I can tell, is that it automatically supports horizontal scrolling of query result sets.
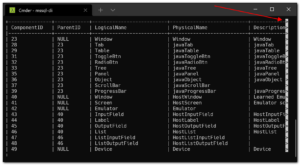
Just use <left><right> arrow keys to scroll the grid left and right as you page through results.
If you don’t use Cmder as your shell, scrolling won’t work like that unless you install something else called PyPager. Which I didn’t do.
Visual Studio Bonus!
Now, all this is well and good, but as they say on late, late night TV: Wait! There’s more!
I spend a lot of time in Visual Studio, so any way to stay there tends to be a positive for me, and one of the most recent additions to VS is built-in Terminal support.
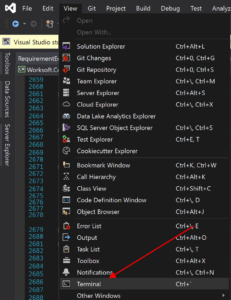
Works a treat and even works with Cmder, so you get all that great Cmder goodness right inside Visual Studio.
But, you can create as many “Terminal Configurations” as you want, so here’s a shot of a few that I have, including one running Cmder directly and another starting the MSSQL-CLI directly to a specific database.